
動画解説
今回のテーマ
本稿では、HubSpotのワークフローを用いたコンタクトや会社レコードの自動マージ機能に焦点を当てつつ、手動でのマージプロセス、データ統合(名寄せ)の意義、そしてマージ実施にあたって留意すべき重要事項に至るまで、HubSpotにおけるレコード統合の全てを詳細に解説します。この記事を通じて、HubSpotのデータ管理を最適化し、ビジネス成果の向上に繋がる具体的な知識と実践的なスキルを身につけていただければ幸いです。
本稿で取り上げるのは、HubSpotのワークフロー機能を活用し、特定のコンタクトや会社レコードといったオブジェクトを自動でマージする手法です。この自動マージ機能は、特に膨大なデータを取り扱う組織にとって、非常に有効な解決策を提供します。手作業によるマージは多大な時間と人的リソースを消費するため、その自動化は運用効率を劇的に改善します。
具体例として、新規登録された会社レコードが既存の会社と同一の法人番号を保有していた場合、ワークフローによって自動的にこれらのレコードを統合することが可能です。この仕組みにより、データ入力時のヒューマンエラーや、異なるシステムからのデータ統合によって生じる重複を未然に防ぎ、常に質の高いデータ基盤を維持できるようになります。さらに、HubSpotアカウント全体で、顧客とのコミュニケーション、CRM管理、マーケティング活動、そしてデータ処理といった一連の業務をより効率的に遂行できるようになります。自動マージは、リードの重複登録を防ぐだけでなく、営業チームが常に最新かつ精度の高い顧客情報に基づいた活動を展開できるよう強力にサポートします。

HubSpotにおけるレコード統合(マージ)の基本概念
HubSpot上では、顧客データ、コンタクト情報、または会社情報に重複が生じた際に、複数のマージ(統合)手法が提供されています。このパートではまず、「名寄せ」という概念の定義から入り、HubSpotにおける「マージ」の具体的な意味合い、そしてマージプロセスにおいて中心的な役割を果たす「プライマリー企業」と「セカンダリー企業」について、それぞれ詳しく掘り下げていきます。
企業情報の統合(名寄せ)とは
「名寄せ」とは、ビジネスにおいて複数のデータベースやシステム内に散在する企業情報を一つに集約し、整理する作業を指します。異なるデータソース間、あるいは同一のデータベース内においても、同じ企業のデータが重複して登録されているケースは少なくありません。このような重複(いわゆる「ダブり」)は、顧客データの正確性を損ね、管理を複雑にするため、解消が不可欠です。
このプロセスでは、企業名、所在地、登録ID、担当者の役職や氏名といった情報を用いて、データベース全体で一致する項目を検索し、関連する情報を統合していきます。企業情報の一元化を図る「名寄せ」は、データベースの品質を維持し、より効果的な顧客管理を実現するために極めて重要な業務なのです。
HubSpotにおける「マージ」の定義
HubSpotでは、このような企業情報の統合プロセスを「マージ」と称します。これは、担当者、コンタクト、取引(Deal)、会社といった様々なオブジェクトのデータを統合する際に用いられる機能です。マージ機能を利用することで、重複する2つの会社情報を1つの会社レコードにまとめ上げることが可能になります。HubSpotのシステムでは、同じ種類のオブジェクトに存在する2つのレコードを統合し、単一のレコードへと結合させます。この際、元々の両方のレコードに記録されていた活動履歴、関連付け、そしてほとんどのプロパティー値が、残る一つのレコードに統合されます。例えば、重複して作成されたコンタクト情報をマージすることで、過去のやり取りの履歴(アクティビティータイムライン)を一つに集約し、顧客との全てのコンテキストを一貫して保持できるようになります。
「マージ」は会社情報だけでなく、コンタクトや取引(Deal)のレコードにも適用可能です。基本的なマージ操作の手順はどのオブジェクトでも共通していますが、各オブジェクトが持つ固有のプロパティーや関連付けの挙動については、統合時に注意を払う必要があります。
プライマリーレコードとセカンダリーレコード
HubSpotでレコードをマージする際、統合対象となる2つのレコードは、最終的に残る「プライマリーレコード」(統合先レコード)と、情報が吸収され消滅する「セカンダリーレコード」(統合元レコード)に分類されます。マージプロセスが完了すると、セカンダリーレコードはシステムから削除され、そのデータや活動履歴がすべてプライマリーレコードに引き継がれます。結果として、プライマリーレコードが最終的な情報源となり、関連する全情報が一元的に集約される形となります。
具体的な例を挙げましょう。誤って「IBM株式会社」と「I.B.M株式会社」という2つの会社レコードが登録されてしまったとします。この場合、顧客データの一貫性を保つため、これらの分散した情報を統一する必要があります。もし「IBM株式会社」のレコードが正しい企業情報を持つと判断されるなら、これがプライマリーレコードとなり、「I.B.M株式会社」はセカンダリーレコードとなります。そして、セカンダリーレコードの情報がプライマリーレコードである「IBM株式会社」へとマージされることになります。
複数の担当者がHubSpotを利用して顧客情報や案件を管理する組織では、上記のような企業情報の重複が発生しやすく、最新の正しいデータが把握しづらくなることがあります。このような状況で企業情報を統合することで、正確な顧客データ管理が可能となり、データ分析の精度向上や業務効率化に大きく貢献します。
HubSpotでレコードをマージするメリットと重要性
「そもそも、なぜ企業情報の統合が必要なのか?」と疑問に感じる方もいらっしゃるかもしれません。企業情報を統合する「名寄せ」には、多岐にわたるメリットが存在します。これらの利点を深く理解することは、HubSpotを用いたデータ管理戦略を最大限に活用し、最適化を図る上で極めて重要な意味を持ちます。
企業情報を管理しやすくなるから
会社情報を統合することで、その管理は格段に効率化されます。しかし、同一企業が複数のレコードとして散在している場合、正確な顧客情報を維持することは極めて困難です。重複データは情報の整合性を損ない、どの記録が最新かつ信頼できるものかを見極めるのを妨げます。管理画面上で、常に正しい会社レコードを迅速に識別できるようにするためには、情報の統合が不可欠です。これにより、データ検索や絞り込みのプロセスが簡素化され、必要な情報にたどり着くまでの時間を大幅に削減できます。
担当者情報を同じ会社レコード内で共有するため
担当者に関する正確なデータを、一つの会社レコード内で一元的に共有するためにも、企業情報の統合は重要です。同一の担当者に関する詳細が複数のレコードに分散していると、情報の欠落や不整合が発生するリスクが高まります。例えば、あるレコードに電話番号、別のレコードにメールアドレスが記録されている場合でも、HubSpotのマージ機能を利用すれば、これらを一つのレコードに集約し、あらゆる情報を統合的に管理することが可能になります。チームメンバー全員が常に最新かつ正確な担当者情報にアクセスできるよう、企業情報の統合を進めましょう。これにより、部門間の連携が強化され、顧客への対応品質を向上させる上で不可欠な基盤が築かれます。
アプローチの質が向上して、営業に活かせるため
会社情報を統合することは、顧客へのアプローチの質を高め、営業活動における成果に直結します。情報を一元化することで、顧客との強固な関係を築くために不可欠なあらゆるデータを、スムーズに把握できるようになります。HubSpotでの情報統合により、例えば以下のような詳細を包括的に管理できるようになり、営業プロセス全体の効率化が図れます。
- 顧客企業のキーパーソンとの過去の対話履歴
- 各部門における担当者の詳細情報
- 歴代の担当者に関する記録
これらの情報を集約することで、営業部門もマーケティング部門も、より洗練された戦略的な顧客アプローチを展開することが可能になります。顧客の行動履歴や過去のコミュニケーション記録が全て一つのレコードに統合されることで、一人ひとりに最適化された提案が可能となり、結果として顧客満足度の向上と契約成立率の上昇が期待できます。
HubSpotでレコードをマージする際の重要な注意点
HubSpotで会社レコードを統合(マージ)する際には、いくつかの重要な留意事項があります。これらのポイントを事前にしっかりと把握しておくことで、意図しないデータ消失やシステム上の混乱を回避し、円滑なマージプロセスを遂行することが可能になります。
これらの注意点を無視して安易に統合作業を進めてしまうと、後になって取り返しのつかない後悔につながる恐れがあります。会社情報のマージに失敗しないためにも、各注意点について事前に十分に確認しておくことを強く推奨します。
一度に統合できるレコードは2件まで
一度に統合できる企業レコードは2件までと決まっています。HubSpotの連携機能では、2つの会社レコードのみを対象とした統合が可能です。これはHubSpotの機能的な制約であり、3社以上の企業情報をまとめて結合することはできません。したがって、3社以上の企業情報をまとめる場合は、2社ずつ順番に統合していく必要があります。2つの会社レコードを統合すると、主要な企業の情報のみが残される仕組みです。
具体例として、「IBM株式会社」「I.B.M株式会社」「株式会社IBM」という3つの企業情報を結合する場合を考えましょう。まず、「IBM株式会社」を主レコードとして「I.B.M株式会社」と統合します。この操作により、「IBM株式会社」のデータのみが維持されます。次に、この残った「IBM株式会社」のレコードを主レコードとし、「株式会社IBM」を副レコードとして再度統合を実行します。この手順を終えると、最終的に「IBM株式会社」のレコードだけが残ります。このプロセスを踏むことで、4社、5社といったより多くの会社レコードでも、一つに集約することが可能です。
統合後のレコード情報はどうなる?優先順位の仕組みを解説
統合された企業情報については、原則として最も新しいデータが優先的に保持されます。HubSpotでは、引き継がれる情報と引き継がれない情報が明確に定められており、それぞれの優先ルールに従って情報が反映される仕組みです。企業情報を統合する前には、この仕組みを十分に理解し、どちらの企業をメイン(プライマリー)として指定するかを慎重に決定する必要があります。
また、もしメインレコードの特定のプロパティが空白であり、サブレコードにその情報が存在する場合には、サブレコードの情報が採用されます。これは、データの欠損を避け、可能な限り多くの情報を維持しようとするHubSpotの設計思想に基づいています。
主要プロパティーにおける優先順位のルール
HubSpotでレコードを統合する際、特定のプロパティーには以下のような優先順位の規則が適用されます。これらの規則を把握しておくことで、統合後のデータがどのように変化するかを正確に見積もることができます。
- ライフサイクルステージ:ファネル(顧客獲得経路)において最も進行したステージが維持されます。(例:サブスクライバー < リード < MQL < SQL < 商談 < 顧客 < エバンジェリスト)
- 作成日:より古い会社の値が保持されます。これは、最初のコンタクトや会社設立の経緯を重視するためです。
- アナリティクスのオリジナルソースタイプ:主企業と副企業の合計ページビュー数と訪問数が表示されます。これにより、両方のレコードのウェブ活動履歴が統合されます。
- アナリティクスのプロパティー:最も古い値が維持されます。
- ドメイン名:会社レコードの場合、主企業が優先されます。
会社レコードの統合における特殊プロパティーと失敗条件
会社レコードの統合には、上記の一般的なルールに加えて、特定の例外的な動作をするプロパティーや、統合が不可能または失敗する条件が存在します。これらの点を把握することは、会社レコードを正確に統合するために不可欠です。
特殊な動作をするプロパティー:
以下の会社プロパティーは、一般的な優先順位ルールに加え、特定の振る舞いを示します。
- ドメイン名:主要な企業が優先されます。
- ライフサイクルステージ:ファネルで最も進んだ段階が保持されます。
- 作成日:より古い会社の値が維持されます。
- アナリティクスのオリジナルソースタイプ:主企業と副企業のページビュー数および訪問数が合算されて表示されます。
- アナリティクスのプロパティー:最も古い値が採用されます。
統合が不可能または失敗する可能性のある条件:
以下のような状況では、会社レコードの統合が実行できないか、途中で失敗することがあります。
- 同じSalesforce IDに紐付けられた2つの会社レコードが存在する場合。
- 統合対象の会社が、ユーザーの権限で許可されていない会社タイプに属している場合。
- 会社が、統合するためのアクセス権限を持たない会社タイプに分類されている場合。
これらの条件は、データの整合性を保ち、アクセス権限を適切に管理するために設けられています。
コンタクト統合時のプロパティー挙動とワークフローの連動について
HubSpotにおけるコンタクトレコードの統合プロセスでは、特定のプロパティーが標準とは異なる挙動を示す場合や、設定済みのワークフローに特有の影響を及ぼすことがあります。特に自動化された運用を行っている組織にとっては、これらの詳細を事前に把握しておくことが極めて重要です。
特殊な処理が適用されるプロパティー:
以下のコンタクトプロパティーは、一般的な優先順位付けルールとは別に、それぞれ固有の処理が適用されます。
- ライフサイクルステージ:マーケティングファネル上で最も進捗している段階が優先的に保持されます。
- 作成日:統合対象の中で最も古いコンタクトの作成日時が引き継がれます。
- アナリティクスオリジナルソースタイプ:プライマリーおよびセカンダリーコンタクト双方の合計ページビュー数と訪問回数が集計され、表示されます。
- アナリティクス関連プロパティー:最も古いコンタクトのプロパティー値が保持されます。
ワークフロー動作への作用:
HubSpotのワークフローにおいて、デフォルト設定では、統合プロセス中にプライマリーコンタクトで発生したデータ変更が、新たなワークフロー登録のトリガーとはなりません。これは、予期せぬ自動化の再実行を防ぐための仕様です。しかし、「既存レコードの登録をトリガーするデータ変更を許可する」というオプションをワークフロー設定で有効化することにより、レコードの結合に伴うデータ更新も、ワークフローの開始条件として機能させることが可能になります。
統合されたレコードは復元不可能
HubSpot上で一度結合された企業情報は、後から元に戻すことができません。セカンダリー企業として統合された情報は完全に消滅し、復活させる手段は提供されていません。この不可逆性は、レコード結合を実施する上で最も留意すべき点の一つです。このため、企業情報を統合する前には、プライマリー企業とセカンダリー企業双方のデータを事前にバックアップしておくことを強く推奨します。
もしセカンダリー企業の情報が必要になった場合は、新たにレコードを作成し、事前に取得しておいたバックアップデータを手動で反映させる必要があります。ただし、この方法でも、システムによって自動生成される情報や、統合によって結合されたアクティビティタイムラインなど、全てのデータを完全に元の状態に復元することは不可能です。この点を十分に理解した上で作業を進めることが肝要です。
関連するコンタクトや取引は全て主レコードに集約
企業のレコードには、担当者を示すコンタクト情報や、商談の進捗を表す取引情報など、さまざまな関連レコードが紐付けられていることが一般的です。これらの関連情報が、レコード統合時にどのように扱われるのか疑問に思う方もいるでしょう。
結論として、統合元の企業(セカンダリー企業)に紐付けられていたコンタクトや取引は、全て統合先の企業(プライマリー企業)へと自動的に関連付けが変更されます。これにより、最終的なプライマリーレコードには、元々関連付けられていた数に加え、セカンダリー企業から引き継がれたコンタクトや取引の数が合計された状態で関連付けられます。この仕組みは、顧客に関する全ての情報を単一のレコードに集約することで、履歴の一元管理や全体像の把握を効率的に行えるという大きな利点をもたらします。
レコード統合が失敗しうるケースとシステム上の制約
HubSpotにおけるレコード統合プロセスは通常円滑に実行されますが、特定の条件下においては処理が失敗する可能性があります。これらのシステム上の制約を事前に把握しておくことは、統合作業を効率的かつ計画的に進行させる上で不可欠です。
レコードの結合処理中は「マージ進行中」といった表示が出ますが、実際に全ての関連アクティビティが新しいレコードに完全に同期されるまでには、最大で30分程度の時間を要する場合があります。
統合失敗の主な要因:
統合処理が失敗する主要な原因の一つとして、システムが定めるレコード結合の制限に抵触している可能性が挙げられます。具体的には、対象レコードが過去に合計250件以上の結合操作に関与していた場合(例:あるコンタクトが130件、別のコンタクトが130件の統合履歴を持つ場合など)、新たな結合を行うことはできません。この上限は、HubSpotシステムの安定したパフォーマンスとデータの一貫性を確保するために設定されています。
この結合上限に到達した際は、レコードを結合するのではなく、新規にレコードを作成するか、あるいは手動でのデータ編集によって情報を整理することが求められます。
HubSpotでのレコード自動マージ機能
HubSpotは、顧客、コンタクト、企業などのレコードが重複した場合に、自動的にそれらを統合する多様な機能を提供しています。これらのマージ機能は、データ整理の手間を大幅に削減し、常に正確で最新の情報を保つのに貢献します。
メールアドレスの一致による自動マージ
コンタクトレコードに関しては、特定の基準に基づいた自動マージ機能が組み込まれています。HubSpotは主にメールアドレスを用いてレコードの重複を特定し、統合を行います。HubSpot CRMは、新しいコンタクトのメールアドレスが既存のレコードと重複していないかを自動的に確認し、識別します。これにより、同じメールアドレスを持つ顧客情報が誤って重複して登録されるのを防ぎます。
さらに、既存の顧客情報において住所や担当者などの詳細が変更された場合でも、メールアドレスをキーとして自動的に名寄せを行い、最新の追加・変更情報を既存レコードに上書きして保存できます。これは、メールアドレスがコンタクトのユニークな識別子として機能するためであり、データの一貫性と正確性を維持する上で極めて有効な仕組みです。
Cookieによる自動マージ
HubSpotは、メールアドレスだけでなく、フォーム送信時に使用されたブラウザのCookieを利用したレコードの統合もサポートしています。Cookieの仕組みは少し複雑に感じられるかもしれませんが、例えば同じブラウザから異なるメールアドレスで複数回フォームが送信された場合でも、HubSpotはこのCookie情報に基づいて関連するレコードをマージします。Cookieは、ユーザーがPCやスマートフォンを通じてウェブサイトにアクセスした際に、自動的にブラウザに保存される小さなデータです。そのため、ウェブフォームやサイトを通じてコンタクトがあった場合、その企業のCookie情報もHubSpot CRM内に記録されます。
顧客がブラウザ経由で何らかのアクションを起こした際、HubSpot CRMは保存されているCookieデータと照合し、重複するレコードがないかを自動的に特定し、統合します。具体的には、顧客が同じPCやスマートフォンから再度コンタクトをとった場合、Cookieによる名寄せが自動的に実行されます。この機能により、匿名でのサイト訪問者が既知のコンタクトとして認識されたり、同一人物が複数のメールアドレスを利用している場合の活動履歴が単一のプロファイルにまとめられたりすることが可能になります。
企業レコードに関しては、HubSpotはウェブサイトのドメインやメールアドレスのドメインを自動的に識別・抽出し、それに基づいてマージを実行します。これにより、たとえ一つの企業が複数のコンタクト先やドメイン情報を持っていても、それらを同一の組織として正確に認識・統合することが可能です。担当者は、この統合された情報に基づき、リードの自動割り当てや通知機能を活用して、最適なタイミングで効果的な対応を行えます。
自動マージ機能の利用に関する注意点
HubSpotの自動マージ機能は非常に有用である一方で、特定の状況においては慎重な設定が求められます。特に、ビジネスモデルによっては、予期せぬレコードの統合が発生するリスクも考慮する必要があります。
例えば、個人顧客や個人事業主をターゲットとするビジネスの場合、GmailやECプラットフォーム(例: BASE)などの共通ドメインに基づいたマージによって、無関係なレコードが統合されてしまう可能性があります。これは、これらのドメインが多数のユーザーによって利用されているため、ドメインのみを基準に自動統合を行うと、本来紐づけるべきではないデータが結合される危険性があるためです。したがって、自動マージ機能を導入する際は、自社の顧客データの特性やビジネスの運用方法を十分に検討し、状況に応じて機能を適切に設定することが不可欠です。
HubSpotで重複レコードを手動で統合する効果的なやり方
HubSpotはWebからのデータ流入に対しては、ある程度自動的な重複排除や統合機能を持っています。しかし、展示会などで収集されたオフラインデータなどでは、意図せず重複レコードが生成されやすい傾向にあります。Data Hubがあれば一括でのレコード統合が可能ですが、それが利用できない場合や、特定のレコードだけを手動で統合したい場合は、一つずつ「HubSpot マージ」機能を使って手作業で処理する必要があります。例えば、重複が疑われるコンタクトの中から統合したいものを選び、詳細画面から手動でマージを進めることになります。

効果的なデータクレンジングはCRM運用において不可欠ですが、重複レコードを発見し、適切に統合する作業は多くの手間を要します。HubSpotのレコードマージ機能は、直感的なユーザーインターフェースが特徴で、比較的誤操作が起きにくい設計です。しかし、プライマリーレコードに統合される側のセカンダリーレコードのデータは消失するため、どの情報を残し、どの情報を消すのかを慎重に判断することが極めて重要です。
本稿では、HubSpotにおける重複レコードの手動マージについて、具体的な手順をステップバイステップでご説明します。今回は企業情報を例に挙げますが、コンタクトや取引レコードの統合も、基本的なプロセスは同じです。
Step1: 統合先レコード(プライマリー)の特定
まず、残したい情報を持つ統合先レコード(プライマリーレコード)を特定します。HubSpotにログインし、画面上部のナビゲーションから「コンタクト」を選び、「会社」をクリックして企業リストを表示します。このリストの中から、統合後も残したいプライマリーとなる企業を選択し、その企業詳細ページへ移動してください。企業ページの左側にある「アクション」ドロップダウンメニューから「マージ」を選択します。これでプライマリー企業が設定されます。

Step2: 統合されるレコード(セカンダリー)の指定
「マージ」を選択すると、レコード統合設定用のポップアップウィンドウが開きます。ここで、プライマリーレコードに統合したいセカンダリー企業を検索して指定します。画面左側の検索フィールドを利用して目的の企業を見つけ、選択してください。選択が完了すると、左側にセカンダリーレコード、右側にプライマリーレコードのプロパティ値が並んで表示され、マージ後のデータがどのように反映されるかの詳細なプレビューが確認できます。
Step3: マージの実行と最終確認
最終確認として、右側に表示されているのが統合先となるプライマリー企業、左側が統合され削除されるセカンダリー企業であることをしっかりと確認してください。間違いがないことを確かめたら、画面左下にある「マージ」ボタンをクリックします。これにより、すぐにデータの統合処理が開始されます。これで、企業レコードの統合作業は完了です。非常に直感的で覚えやすい操作プロセスです。マージが完了すると、セカンダリーレコードはシステムから削除され、自動的にプライマリーレコードのページへとリダイレクトされます。統合されたデータが期待通りに反映されているか、念入りに最終確認を行いましょう。
HubSpotワークフローによるカスタム自動マージ機能の構築
HubSpotの強力なワークフロー機能を活用することで、より洗練された条件に基づくレコードの自動マージを実現できます。この機能は、特にHubSpot標準のマージ機能では対応しきれない、特定の業務要件に合わせた重複データ処理に際して非常に効果を発揮します。
本稿では、カスタムワークフローを用いてレコードのマージプロセスを自動化する方法について解説します。
Step1 ワークフローの作成とカスタムアプリ「マージアクション」の導入
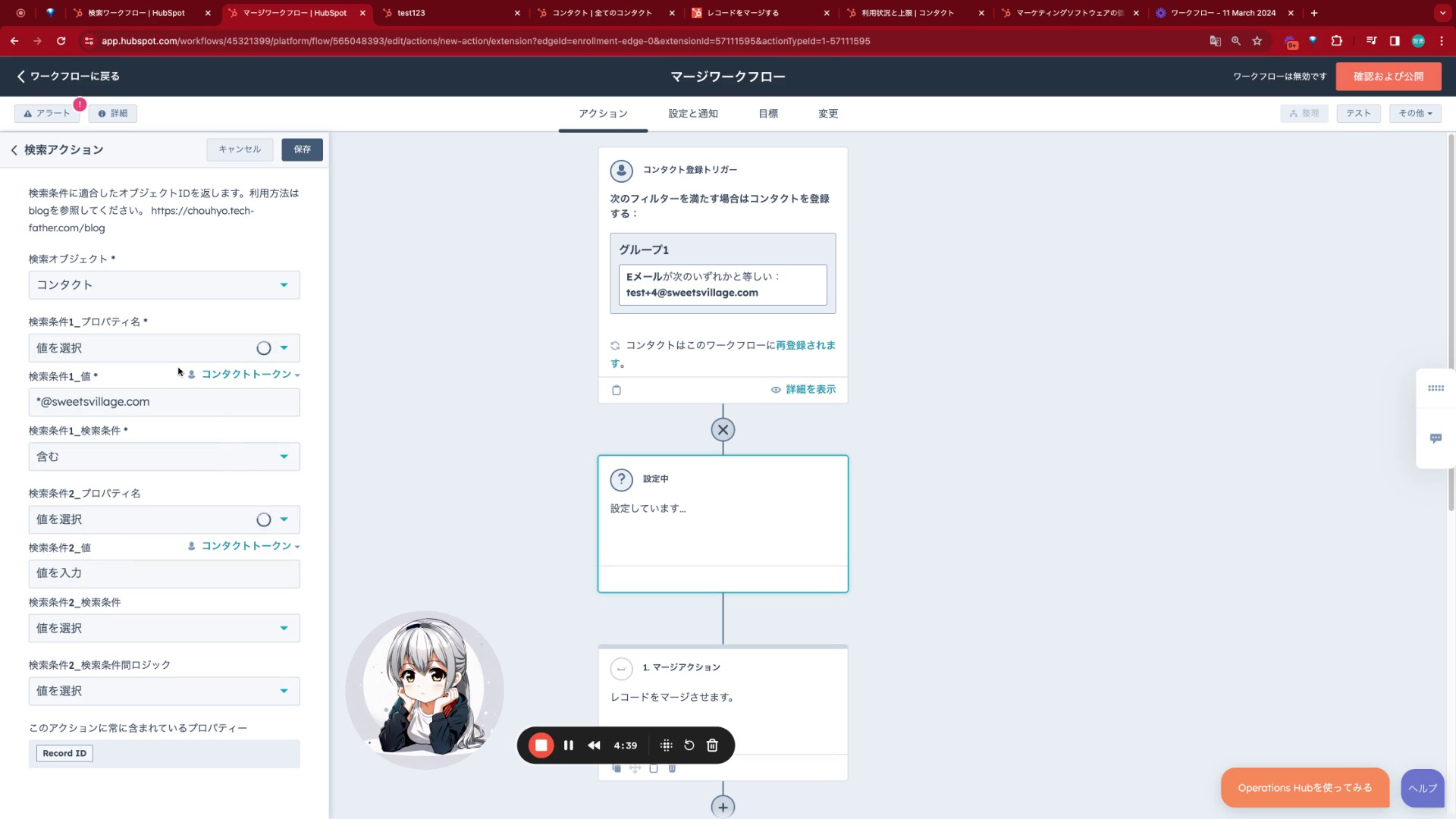
最初に、HubSpot上で新規ワークフローを立ち上げます。対象となるオブジェクト(例:企業情報、連絡先)に応じて適切なワークフロータイプを選定してください。次に、カスタムワークフローのアプリケーションリストから「マージアクション」を選択し追加します。このアクションは、HubSpotの連携機能を通じて、指定された二つのレコードを自動的に統合する主要な機能を提供します。
Step2 マージアクションの詳細設定
「マージアクション」を選択すると、以下の二つの必須入力フィールドが表示されます。
- マージ元ID(セカンダリーレコードID):統合される側のレコードを一意に識別するIDを設定します。このレコードは処理後に削除され、そのデータはマージ先へと移行します。
- マージ先ID(プライマリーレコードID):最終的に残るメインのレコードを一意に識別するIDを指定します。すべての情報は、この指定されたレコードに集約されます。
重要な点として、マージ先のレコードが最終的に存続することにご留意ください。また、ワークフローの実行トリガーとなるオブジェクトにも注意が必要です。通常、連絡先は連絡先、企業は企業といったように、同じ種類のオブジェクト間でのマージが前提となりますので、ワークフロー作成時に適切なターゲットオブジェクトを選択しておくことが重要です。
Step3 検索アクションとの連携によるIDの動的抽出
マージアクションは、検索アクションと組み合わせることでその真価を発揮します。検索アクションの詳細については別途ご確認ください。この検索アクションを活用することで、特定の基準に合致するレコードをリアルタイムに検出し、そのユニークIDをマージアクションの入力値としてシームレスに連携させることが可能になります。
具体的な例としては、法人番号が一致するレコードを自動的に探し出し、そのオブジェクトIDを抽出することができます。抽出されたIDを用いて自動マージを実行することで、例えば後から登録された重複データを自動的に統合するといった運用が実現可能です。これにより、企業の登記情報が更新された際など、特定の識別情報が重複した場合でも、システムが自動的に適切なマージ処理を行うことができます。
カスタム自動マージにおける運用上の注意点
HubSpotにおけるレコードのマージ機能は強力ですが、一度実行すると取り消せない特性があります。そのため、完全に自動化するのではなく、人間の目による確認プロセスを組み込むことを強くお勧めします。例えば、HubSpotのワークフロー機能を活用し、マージ候補となるレコードに特定のカスタムプロパティ(例:「統合承認待ち」など)を自動で付与します。その後、担当者がこれらの候補をレビューし、手動で承認アクションを行った後に、最終的なマージ処理が実行されるような運用フローを構築することが考えられます。これにより、データの正確性を維持し、意図しないデータ統合のリスクを大幅に削減することが可能になります。
さらに、コンタクトのマージに関連する重要な留意点として、ワークフロー内で統合操作が実行された際、統合後の主要コンタクト(プライマリーコンタクト)は、既定ではそのワークフローに自動的に再登録されないという挙動があります。もし、統合されたプライマリーコンタクトが引き続きワークフローの処理を受ける必要がある場合は、該当するワークフローの設定でこの再登録オプションを明示的に有効化する必要があります。
マージされたレコードの履歴とプロパティーを確認する
HubSpotプラットフォームでは、以前に統合されたレコードの履歴を専用のプロパティを通じて追跡・確認することができます。この機能は、データ整合性の監査、トラブルシューティング、または過去のデータ変更を把握する上で極めて価値の高いツールとなります。この履歴プロパティは、個別のレコード詳細画面からアクセスできるほか、特定の条件で全レコードをフィルタリングし、統合に関与したレコードを一覧表示することも可能です。
個々のレコードで「マージされた[レコード]ID」プロパティーを確認
個別のレコード単位で統合履歴プロパティを参照するには、以下のステップを踏んでください。
- 対象のレコードビューを開きます。
- 左側のプロパティパネル下部にある「すべてのプロパティを表示」をクリックします。
- 展開されたセクションの中から「このレコードに関する情報」を見つけて開きます。
- そこに表示される「マージされた[レコード]ID」プロパティをチェックします。このプロパティには、そのレコードが統合処理の一部として扱われた際に結合された、関連するレコードのユニークIDが記録されています。
特定のオブジェクトの全レコードでマージ履歴をフィルタリングして確認
特定のオブジェクトタイプ(例:コンタクト、会社など)全体で、統合履歴を持つすべてのレコードを効率的に特定するには、次の手順を実行します。
- 該当するレコードタイプのインデックスページへ移動します(例:「コンタクト」→「コンタクト」を選択)。
- 現在のビュー(「すべてのコンタクト」ビューや作成済みのカスタムビューなど)を選択します。
- ビューの表示列を編集するオプションを選び、「マージされた[レコード]ID」プロパティをテーブルの列に追加します。
- このプロパティを使用してフィルタリング機能を実施し、値が設定されているレコードのみを表示するように設定します。これにより、過去に統合された、あるいは統合プロセスに関与したすべてのレコードが一覧として表示され、俯瞰的に確認できるようになります。
これらの機能を利用することで、どのレコードがいつ、どのような状況で別のレコードと統合されたのかを正確に追跡し、組織のデータ変更履歴を包括的かつ詳細に把握することが可能になります。
参考記事
https://knowledge.hubspot.com/ja/records/merge-records
まとめ
HubSpotにおける顧客レコードの統合は、正確性と一貫性を保ったデータ基盤を築く上で極めて重要です。手動での結合だけでなく、メールアドレスやCookieを基にした自動結合、さらにはワークフローを用いた独自の自動統合といった、HubSpotが提供する多岐にわたるデータ連携手段が存在します。
ただし、マージ操作は一度実行すると取り消しができない不可逆的なものであり、一度に3つ以上のレコードを統合できないといった重要な制約が存在します。特に、結合時のプロパティ値の優先順位や、関連付けられたオブジェクトの連動について事前に把握しておくことは、データの不測の消失を防ぎ、意図した通りの成果を得るために不可欠です。本稿で説明した手動および自動でのマージ手順と留意点を活用し、HubSpot内のデータを常に最適な状態に保つことで、マーケティングや営業活動の生産性を最大限に引き上げましょう。的確なデータ運用こそが、事業成長を促進する強固な土台となります。
HubSpotでレコードをマージするとは具体的にどういうことですか?
HubSpotにおけるレコードのマージとは、重複して存在する複数のレコード(例:コンタクト、企業、商談など)を単一のレコードへと集約する手順を指します。この操作により、両方のレコードに記録されていた活動履歴、関連付け、そして大部分のプロパティ値が統合され、結果としてデータの一貫性と精度が維持されます。統合後、セカンダリー(副)レコードは削除され、その情報はプライマリー(主)レコードに集約される形となります。
マージできるレコードの数に制限はありますか?
はい、HubSpotのマージ機能にはいくつか制約があります。まず、一度に統合できるレコードの数は最大で2つまでです。したがって、もし3つ以上の重複レコードが存在する場合は、それらを2つずつ段階的にマージしていく必要があります。加えて、システムには、過去に合計250件以上のマージ処理に関与したレコードは、それ以降のマージが不可能となるという制限も設けられています。
一度マージされたレコードを取り消すことはできますか?
残念ながら、HubSpotで一度実行されたレコードのマージ操作を取り消すことはできません。このプロセスは完全に元に戻せない性質を持つため、実行に移す前に、対象となるレコードの内容を徹底的に確認し、必要であればデータのバックアップを確保することを強くお勧めします。特に機密性の高い情報やビジネス上重要なデータが含まれている場合は、細心の注意を払って判断してください。
レコードのマージ時、どの情報の優先順位が適用されますか?
基本的に、マージ後のレコードでは、最も新しい情報が優先されて保持されます。しかし、いくつかの特定のプロパティについては、異なる優先順位が適用される場合があります。例えば、ライフサイクルステージはファネルで最も進んだ状態、作成日は古い日付、アナリティクス関連プロパティは合計値または最も古い値が採用されます。また、会社ドメインに関しては、プライマリーレコードの値が優先されます。もしプライマリーレコードの特定のプロパティが空欄で、セカンダリーレコードに値がある場合は、セカンダリーレコードの値が引き継がれます。
レコードのマージプロセスを自動化できますか?
はい、HubSpotではレコードマージの自動化が実現可能です。標準機能として、メールアドレスの同一性やCookieの一致に基づいて自動的にマージを行う設定が用意されています。さらに高度な自動化を目指す場合、HubSpotのワークフロー機能とカスタムワークフローアクションを連携させることで、例えば法人番号の一致といった、より具体的かつ複雑な条件に基づいた独自の自動マージルールを構築することもできます。
マージされたレコードの活動履歴や関連オブジェクトはどのように扱われますか?
マージが実行されると、セカンダリーレコードに記録されていたあらゆる種類の活動履歴(メールのやり取り、電話記録、ミーティング履歴など)は、すべてプライマリーレコードに統合されます。同様に、セカンダリーレコードに紐付けられていた全ての関連オブジェクト(例えば、コンタクト、会社、取引、チケットなど)も、プライマリーレコードへの関連付けが自動的に移行されます。このプロセスにより、過去の全ての履歴情報と関連データが一箇所に集約され、統合された単一のレコードで包括的に管理できるようになります。





